

Pourquoi avons-nous développé une API RESTful avec Flask en Python ?
Une API RESTful ? Quelles technos et pourquoi ce choix ?
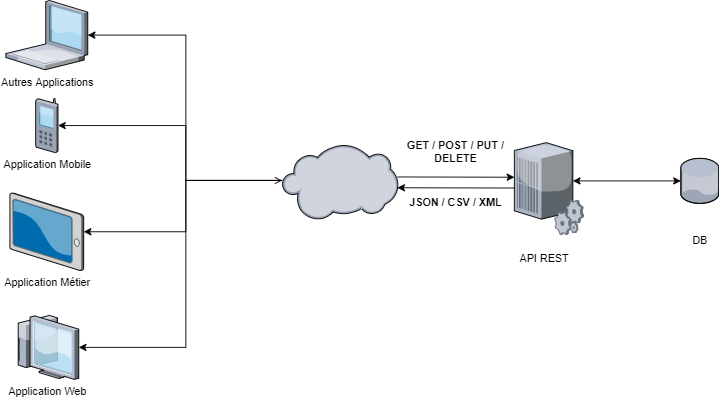
API Web RESTful
Pourquoi une API (Application Programming Interface) RESTful (REpresentational State Transfer) ? Mettre en place cette technologie permet de séparer la partie Front (visuelle) de la partie Back (données). La norme REST apparue dans les années 2000 (par Roy Fielding) apporte également une norme architecturale, ainsi que les règles permettant d’avoir une application pérenne, modulable, flexible et évolutive !
On rappelle qu’une API REST doit respecter des règles telles que l’identification des ressources par l’URI (Uniform Ressource Identifier) ce qui implique une grande rigueur dans la construction de ses URLs. Chaque ressource doit avoir 4 actions liées :
- GET pour récupérer un ou plusieurs objets,
- POST pour créer un objet,
- PUT pour le modifier,
- et DELETE pour la suppression d’un objet.
Chacune de ces actions doit impérativement renvoyer une réponse HTTP, que ce soit pour remonter une erreur dans l’exécution ou bien la représentation de l’objet demandé. Pour cela on utilise principalement le JSON qui est interprété par quasiment tous les langages de programmation clients (on pourrait tout de même renvoyer des réponses au format XML, HTML ou encore CSV selon les besoins).
Ces APIs rencontrent une problématique : elles sont de base ouvertes et utilisables de manière publique, on se doit donc de mettre en place un système d’authentification dans le cas où l’on souhaite que nos données soient accessibles de manière privée.
Python plutôt que PHP… Pourquoi ?
Notre but étant de mettre en place une application Backend permettant d’y accéder depuis différentes applications externes (Application mobile, site internet, intranet, ou logiciel métier), nous avons décidé de partir sur une application développée en Python. Mais pourquoi pas en PHP (avec notamment le Framework Symfony) ?
En effet les deux langages permettent de répondre parfaitement à nos besoins.
De plus, les deux offrent une documentation bien fournie, une communauté très active sur les réseaux ainsi que sur les sites communautaires tels que StackOverflow. Si l’on reprend les prérequis d’une API REST, les deux langages feraient parfaitement l’affaire, mis à part le fait que, nous avons des besoins spécifiques, notamment dans ce qui est du domaine de l’analyse spatiale et graphique, qui fera objet d’un futur article.
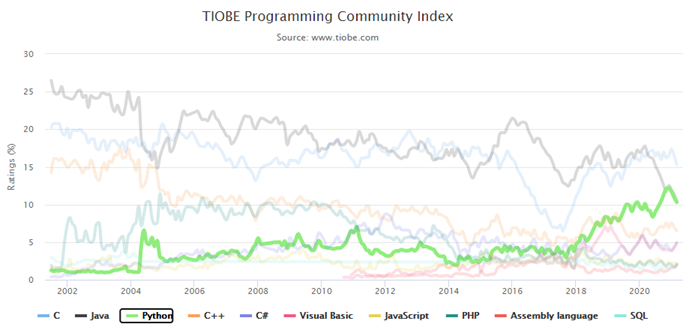
Le PHP évoluant beaucoup ses dernières années, notamment avec la version 7, il propose un moteur plus puissant que son concurrent mais reste à ce jour toujours très permissif au niveau des bonnes pratiques de développement. Python demeure à ce jour un langage stable et strict, possédant de nombreuses librairies complètes (notamment pour les données géographiques) et d’autres que l’on maîtrisait déjà (Swagger, JWT tokens, Pandas, etc…). Sans compter que Python est un des langages de programmation des plus plébiscité dans le développement (comme on peut le constater dans les statistiques remontées par TIOBE (TIOBE Table Index).
Pour ce qui est de l’environnement de développement, nous travaillons sous Windows 10 Pro, avec Python 3.8 et comme IDE Visual Studio Code. Ce dernier propose quant à lui un certain nombre d’outils parfaitement fonctionnels et adaptés pour des projets web aussi bien Frontend que Backend. Nous travaillons sur chaque projet via un environnement virtuel géré par la package Pipenv, afin de pouvoir développer de n’importe où sans contraintes d’installation de serveur de développement (autre que Python).
Flask plutôt que Django. Pourquoi ?
La problématique rencontrée par la suite s’est portée sur le choix entre le Framework Django ou le micro-Framework Flask. Ces deux Frameworks sont à ce jour à la lutte en termes d’utilisation avec Python (comme le présente les statistiques de Jetbrains sur Python en 2020). Pour ce qui est de l’activité au sein de la communauté open-source de développeurs, on garde cette proximité entre ces deux-là comme le fait remonter Open Hub dans leur comparatif de projets :
| Django | Flask | |
| Premier Comit | 2005 | 2010 |
| Contributeurs | 2390 | 714 |
| Utilisateurs* | 520 750 | 569 489 |
| Commentaires | Faible | Moyen |
Chiffres remontés par OpenHubs.net en comparaison des deux Frameworks courant fin 2020. Source : openhub.net
Plusieurs raisons nous ont conduit à ce choix mais la principale reste que Flask est un micro-Framework, il est à ce jour très léger, ce qui fait de lui un Framework des plus flexibles à l’installation et la configuration (on peut comparer avec le langage PHP : Symfony qui est lui aussi un des plus légers Framework de ce langage). Cela implique donc que l’on doit effectuer une veille technologique approfondie afin de sélectionner les dépendances que l’on a besoin pour étoffer notre projet : ce qui appuie en plus le fait que, chez Exo-Dev, nous développons des outils sur-mesure ! A l’instar de Django, qui intègre de nombreux composants, comme le fait qu’il impose l’utilisation de son propre ORM. Il est quant à lui principalement utilisé pour des applications avec des interfaces web, nous n’en avons pas besoin du fait que l’on met en place une simple API RESTful sans interface graphique.
De l’installation de Flask à la mise en production de l’API
La mise en place de l’architecture du projet
Le sur-mesure en termes de développement, afin qu’il soit rentable niveau réutilisation de code, se doit d’être bâti sur une base commune et fonctionnelle : un Boilerplate.
Nous avons donc installé Flask afin d’avoir la main mise sur l’architecture de l’application et sur l’ensemble des fonctionnalités à implémenter : nous partons sur une application modulable avec le Python en Programmation Orienté Objet.
Afin de gérer les dépendances, nous avons utilisé PyPi, un gestionnaire d’installation de packages pour Python qui permet d’avoir un fichier de dépendance pour utiliser le projet.
Des fichiers de variables d’environnement nous permettent de définir les informations critiques que ce soit au niveau des informations de connexion aux bases de données ou aux clés de cryptage selon l’environnement dans lequel nous nous trouvons.
L’utilisation du package Python Pipenv nous permet de générer un environnement de développement virtuel dans lequel l’API tournera, avec une gestion des logs afin de journaliser les erreurs côté serveur.
On profite du système de Blueprints que propose Flask afin de découper par fonctionnalité les différents points d’entrée de l’API, ce qui nous permet de rendre l’application modulaire et de pouvoir facilement ajouter, ou retirer des fonctionnalités sans impacter le fonctionnement global de l’application ce qui rend le code totalement flexible.
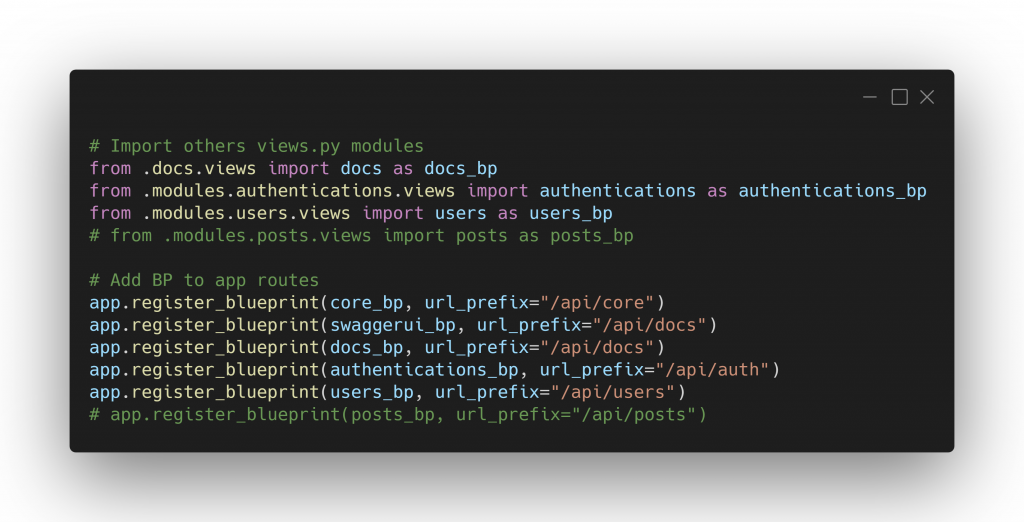
Pour la gestion des tests unitaires, nous utilisons le package de base de python : pytest, qui permet de tester l’ensemble de nos routes en vérifiant tous les cas d’erreurs possibles.
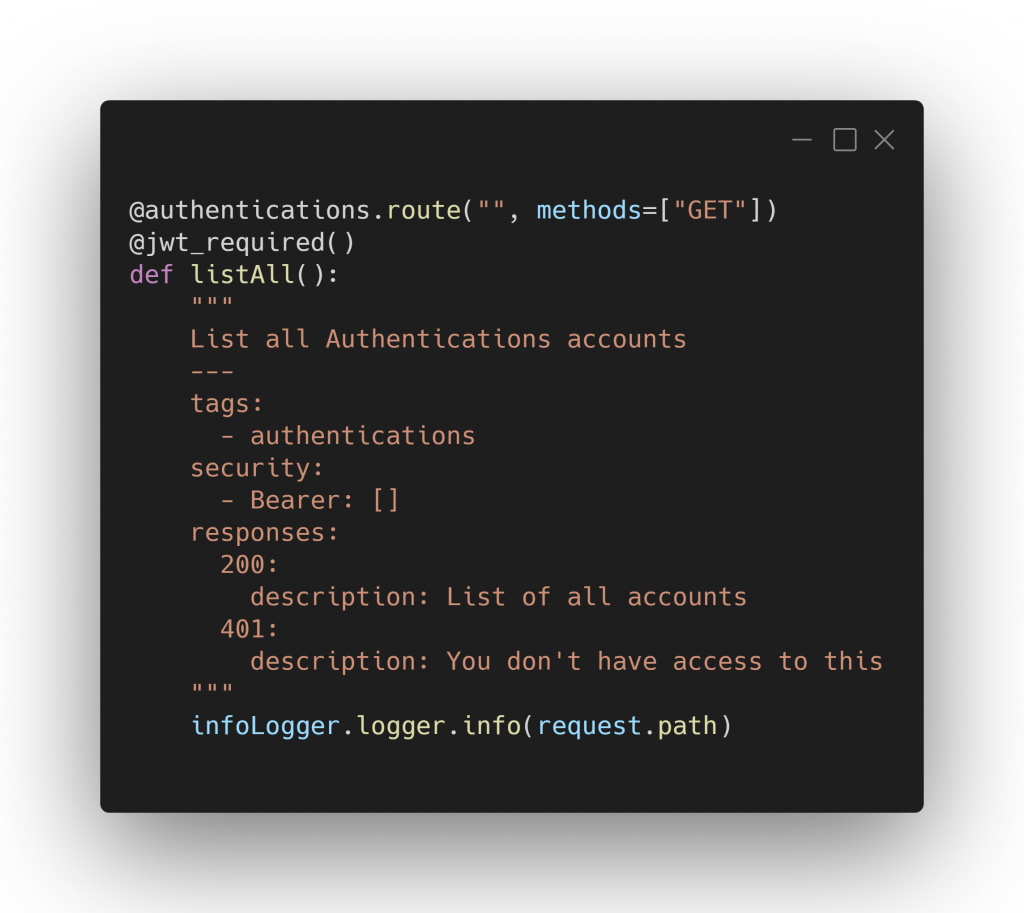
Pour ce qui est de l’authentification avec restriction d’accès pour certaines entrées de l’API (toutes celles qui doivent êtres privées) on utilise le package flask-jwt-extended afin de pouvoir gérer nous-même la création du Token qui sera stocké côté client, envoyé dans chaque requête HTTP dans le header, et vérifié automatiquement grâce au package via des annotations.
Afin de gérer des données spatiales, nous avons mis en place une base de données grâce au puissant SGBD PostgreSQL. À savoir que Flask permet d’utiliser la quasi-totalité de ces derniers (SQLite, SQLServer, MariaDB, MongoDB, etc…).
Les modules intégrés et les problématiques rencontrées
La première problématique rencontrée était de mettre en place un ORM (Object Relational Mapping) dans le but de pouvoir interagir avec notre BDD par le biais d’objets Python.
Sans ORM, votre application risque de se transformer très rapidement en programmation spaghetti.
De plus, dans tous les langages de programmation il n’est pas recommandé de mélanger des requêtes SQL au sein du code pour ne pas le rendre très vite indigeste… Sans compter qu’en utilisant un langage Orienté Objet, il serait illogique de ne pas mettre en place un ORM. Pour cela nous avons fait le choix de SQLAlchemy. Utilisé de manière assez commune avec Python, il offre la possibilité de se connecter assez facilement à différents SGBD en choisissant les bons connecteurs. Attention, travaillant de base avec Flask, on peut utiliser des packages développés spécialement pour comme : flask-sqlalchemy ! (Oui, pas besoin de chercher bien loin, ce qui est principalement le cas pour l’ensemble des dépendances du projet), et ne pas se limiter au package sqlalchemy de base. En effet ce package intègre des processus implémentés spécifiquement pour Flask afin de faciliter son installation ainsi que sa configuration.
La seconde problématique était de trouver comment sérialiser nos objets récupérés de la BDD via SQLAlchemy en JSON ! En effet, nous utilisons la fonctionnalité de base de Flask qui est la fonction jsonify. Cependant, cette fonction requiert une connaissance de chaque champ que l’on souhaite sérialiser, et que l’on doit spécifier à chaque fois ! C’est pour cela que l’on fait appel à un ODM (Object Document Mapping) afin de pouvoir « documenter » nos objets : Marshmallow étant parfait pour cette situation car il est principalement utilisé en complément de SQLAlchemy. Dans le même principe : nous avons fait appel au package flask-marshmallow qui est développé pour Flask. Attention ! c’est là qu’il faut bien étudier ces packages, pour que Flask puisse correctement sérialiser vos objets SQLAlchemy grâce à Marshmallow, pensez à bien ajouter le package marshmallow-sqlalchemy ! C’est à ce niveau là qu’on se rend compte du niveau de flexibilité, et de complexité de Flask avec tous les packages que Python propose.
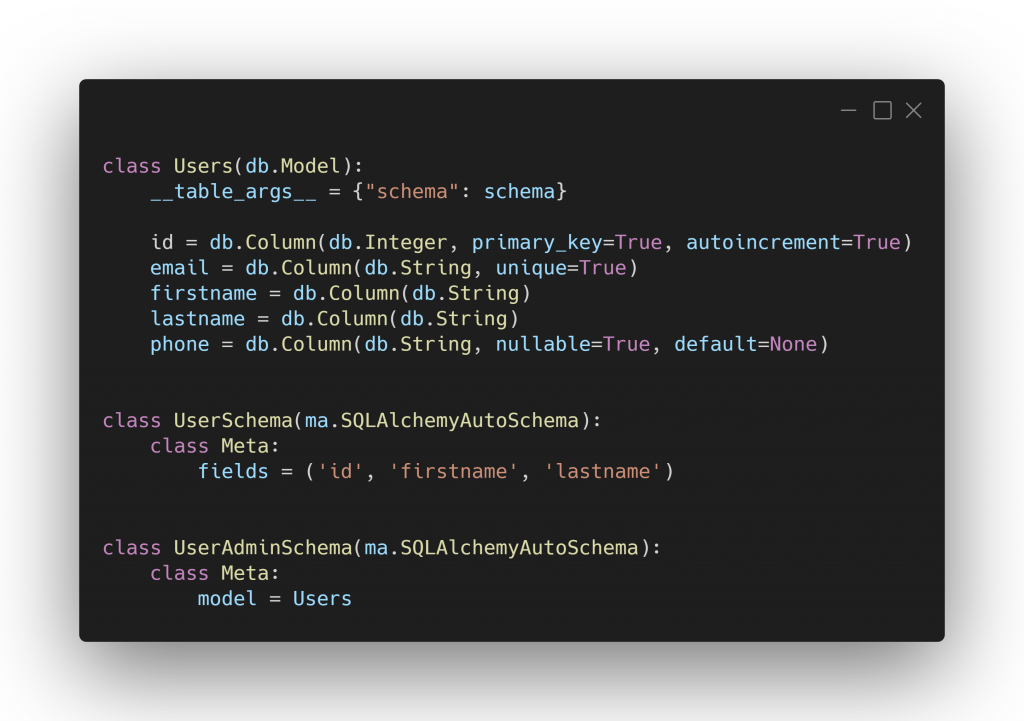
On se retrouve ainsi à déclarer ses modèles grâce à SQLAlchemy, à les sérialiser grâce à Marshmallow via jsonify, puis le contrôle des routes se fait grâce aux Blueprints. On retrouve la partie Controller et Model du fameux modèle MVC (Model View Controller), car on reste sur une API (même si on pourrait présenter le rendu JSON comme la partie View).
La problématique suivante concerne maintenant l’architecture propre du projet, que l’on souhaite construire de manière flexible et modulaire !
Pour cela nous avons eu besoin de définir nos principaux packages de manière globale dans l’application notamment pour SQLAlchemy, Marshmallow, Logger et Swagger.
Dans la même logique : Swagger ! Outil incontournable pour vérifier nos données ainsi que nos points d’entrée d’API… Cependant il faut faire attention, si vous souhaitez mettre en place une interface Swagger-UI, il vous faudra installer le package flask-swagger dans un premier temps, afin de commenter chaque route que vous souhaitez remonter au niveau de votre interface Swagger UI, puis le package flask-swagger-ui qui vous permettra de configurer cette dernière qui sera la route d’accès. Attention, pour chaque point d’entrée d’API, il faudra bien vérifier si ces derniers requièrent un token d’authentification JWT…
Enfin pour la livraison du projet en production, vous pouvez directement cloner votre projet sur le serveur de production, créer son environnement virtuel via pipenv, et exécuter votre API en environnement de production comme on pourrait la lancer en développement. De notre côté, on a même préparé un petit script en Bash (launch.sh), qui permet de lancer l’application dans un screen détaché, afin de l’avoir en tâche de fond du serveur.
Ce que l’on retiendra
Après de longues heures de veille technologique sur ce sujet, on remarque que très peu de projets sont identiques du fait de la grande flexibilité de Flask (sauf depuis la sortie du package flask-restplus, que nous n’avons pas mis en place simplement car nous avions déjà défini notre base Flask). Cependant ce micro-Framework Flask répond parfaitement à nos besoins de créer du sur-mesure pour nos clients, avec la modularité souhaitée de notre application. Ce projet Boilerplate possède ainsi une structure complète : ORM, ODM, Swagger UI, Logger, gestion d’authentification, tests unitaires, et même ses classes d’envoi de mail. Et tout ceci pouvant être déployé en une dizaine de minutes !
La mise en place de ce Boilerplate a demandé beaucoup de veille/auto-formation qui est dû au fait que Flask est très limité niveau fonctionnalités (ce qui en fait sa force) car en tant que développeur on se doit de tout installer et configurer l’ensemble des packages en pensant bien à vérifier leur compatibilité d’utilisation avec Flask !
L’avantage de ce travail, c’est qu’il permet de connaître parfaitement son projet, nous avons mis en place nous-même notre propre architecture, installé et configuré comme nous le souhaitions de A à Z. Un gros travail qui permet par la suite de pouvoir réutiliser cette base pour autant de projets d’API que l’on souhaite réaliser par la suite.
On parlait précédemment de la partie View du modèle MVC… Mais qu’en est-il de la partie Front ? Quelle technologie avons-nous utilisé pour se connecter à cette API ?
Nous vous en parlerons bientôt 😉